
공부하는 안씨의 기록
[모델학습] 하이퍼파라미터(Hyperparameter), 학습 결과 본문
하이퍼파라미터란?
하이퍼파라미터(Hyperparameter)는 모델 학습 과정에서 인간이 직접 설정하는,
즉 사용자가 직접 설정해야 하는 변수이다.
이는 모델의 성능과 학습 속도에 큰 영향을 미치는 중요한 요소로, 학습 중 자동으로 조정되지 않는다. 하이퍼파라미터는 모델의 최적화 과정과 구조를 결정하며, 이를 적절히 설정하는 것이 성공적인 모델 학습의 핵심이다.
하이퍼파라미터의 종류
하이퍼파라미터는 사용자가 직접 설정할 수 있는 변수로, 주로 학습률(Learning Rate), 배치 크기(Batch Size), 에포크(Epoch)등이 있다. 옵티마이저와 드롭아웃 또한 사용자가직접 설정할 수 있는데, 옵티마이저는 최적화 알고리즘의 역할을 수행하고, 드롭아웃은 과적합을 막기위한 방법 중 하나로 사용된다.
자세한 예를 살펴보기 위해, 모델 학습을 진행하며 작성했던 코드의 일부를 가져왔다. 모델 학습을 위한 파라미터가 정의되어있으며, 맥락을 위해 학습을 진행했던 모델 내부 관련 코드는 지워두고, 이번 게시글에 필요한 부분에 대해서만 보여주고자 한다.
# 모델 학습
def train_model(
dataset_path,
output_dir="./trained_model",
learning_rate=5e-5,
batch_size=1,
num_epochs=10,
logging_steps=1,
eval_strategy="epoch",
save_strategy="epoch",
metric="eval_loss",
greater_is_better=False,
report_to=["comet_ml"]
):
# 데이터셋 로드
dataset_dict = load_from_disk(dataset_path)
train_dataset, eval_dataset = dataset_dict["train"], dataset_dict["eval"]
# 옵티마이저 설정
optimizer = torch.optim.Adam(prompt_encoder.parameters(), lr=learning_rate)
# 학습 파라미터 설정
training_args = TrainingArguments(
output_dir=output_dir,
evaluation_strategy=eval_strategy,
save_strategy=save_strategy,
learning_rate=learning_rate,
per_device_train_batch_size=batch_size,
num_train_epochs=num_epochs,
logging_steps=logging_steps,
load_best_model_at_end=True,
metric_for_best_model=metric,
greater_is_better=greater_is_better,
report_to=report_to,
)
# Trainer 설정
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
optimizers=(optimizer, None)
)
# 모델 학습
trainer.train()
# 모델 저장
model.save_pretrained(output_dir)
1. 학습률 (Learning Rate)

학습률은 가중치를 업데이트할 때 기울기 방향으로 이동하는 크기를 결정한다.
- 작은 학습률: 수렴이 안정적이지만 시간이 오래 걸린다.
- 큰 학습률: 학습이 빠르지만 최적값을 지나쳐 발산할 위험이 있다.

위 수식에서 η은 학습률(Learning Rate)이다.
적절한 학습률을 선택하는 것이 매우 중요하며, 일반적으로 학습률 스케줄링이나 Adaptive Learning Rate (예: Adam Optimizer)가 사용되기도 한다.
2. 배치 크기 (Batch Size)
배치 크기(Batch Size)는 한 번의 가중치 업데이트에 사용할 데이터의 개수를 의미한다.
- 작은 배치 크기 (예: 8, 16): 빠른 업데이트가 가능하지만 기울기 진동이 크다.
- 큰 배치 크기 (예: 256, 512): 더 안정적인 학습이 가능하지만 메모리 사용량이 증가하고 계산 시간이 늘어난다.
- 중간 배치 크기 (예: 32, 64, 128): 학습 속도와 안정성의 균형을 제공하며 가장 자주 사용된다.
일반적으로 배치 크기를 늘림으로서 학습을 안정적으로 진행하며, 이 경우 GPU가 필요하다. 나의 경우 GPU 없이 노트북에서 학습을 진행하여 batch_size=1로 설정했던 경험이 있다.
3. 에포크 (Epoch)
에포크(Epoch)는 전체 데이터셋을 모델이 몇 번 학습할 것인지를 나타낸다.
1 에포크는 모든 데이터를 한 번 순회하며 학습하는 것을 의미한다.
- 에포크 수가 적으면 학습이 부족(Underfitting)할 수 있다.
- 에포크 수가 너무 많으면 과적합(Overfitting)이 발생할 수 있다.
에포크 수를 결정할 때는 검증 데이터의 손실 감소 추세를 참고해야 하며, 조기 종료(Early Stopping) 기법을 활용하기도 한다.
4. 옵티마이저 (Optimizer)

옵티마이저는 손실 함수의 기울기를 기반으로 가중치를 조정하는 최적화 알고리즘이다.
- SGD (Stochastic Gradient Descent): 단순하지만 진동이 크다.
- Momentum: 이전 기울기를 반영해 진동을 줄인다.
- Adam (Adaptive Moment Estimation): 학습률을 자동으로 조정하며, 빠르고 안정적이다.
Adam은 많은 딥러닝 모델에서 기본으로 사용된다.
5. 드롭아웃 (Dropout)
드롭아웃(Dropout)은 과적합을 방지하기 위해 학습 중에 랜덤으로 일부 뉴런을 비활성화하는 기법이다. 드롭아웃 비율은 0과 1 사이의 값으로 설정하며, 일반적으로 0.3 ~ 0.5 사이가 많이 사용된다.
하이퍼파라미터 조정 전략
- 하이퍼파라미터 검색(Grid Search, Random Search): 여러 조합을 시도해 최적의 하이퍼파라미터를 찾는다.
- 학습 곡선 모니터링: 학습 중 손실 함수와 정확도 추이를 확인해 학습이 과적합되거나 부족하지 않도록 조정한다.
- 검증 데이터 사용: 학습 데이터뿐만 아니라 검증 데이터의 성능도 함께 모니터링해 하이퍼파라미터를 조정한다.
위와 같이 기존 파라미터로 모델 훈련을 진행했을때, comet을 통해 학습 진행 결과를 평가해보았더니 아래와 같은 결과가 나타났었다.



eval의 손실이 학습을 진행하며 점점 증가하는 것을 눈에 띄게 확인할 수 있다. 또한, loss 및 train loss도 학습 진행 중 증가하는 등, 전체적으로 이번 학습은 잘 진행된 학습이라고 볼 수 없다. (만약 loss VS step은 감소하더라도, eval/loss VS step이 감소하지 않는다면 잘못 된 학습이라고 볼 수 있다.) 나는 여기서 학습률(Learning Rate)을 변경해서 학습을 진행해보았다. 변경된 하이퍼파라미터는 아래와 같다.

위와 같이 학습률을 줄여서 진행해보았다. 그러자 아래와 같은 결과가 나타났다.
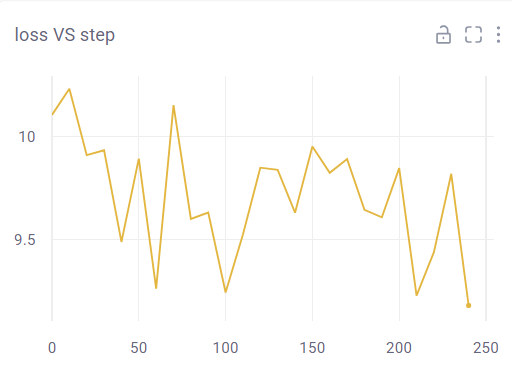
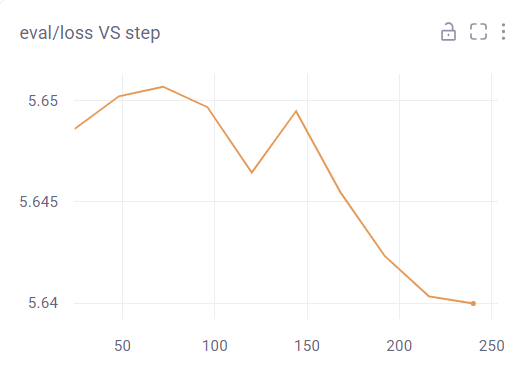

우선, 전체적으로 세 그래프 모두 약간의 불안정한 개형을 가지고 있으나 전체적인 양상은 손실이 감소하고 있음을 확인할 수 있다. (배치 사이즈, 에포크 등을 늘리면 좀 더 유의미한 학습 결과를 볼 수 있을 것으로 예상된다.) 우선 노트북 환경으로는 이렇게 학습을 간단하게 진행해보았다. 실제로는 배치 크기를 늘리고, 에포크를 훨씬 늘려서 진행하면 좀 더 안정적인 개형을 확인할 수 있을 것으로 예상된다.
이와 같이, 하이퍼파라미터를 수정해가며 학습 곡선을 관찰하고, 이를 바탕으로 하이퍼파라미터 등을 업데이트 하는 방식으로 모델 학습을 진행할 수 있다.
정리
하이퍼파라미터는 딥러닝 모델의 학습 과정에 직접적인 영향을 미치는 중요한 요소이다. 학습률, 배치 크기, 에포크 수, 옵티마이저 선택 등은 모델의 최종 성능을 좌우할 수 있다. 적절한 하이퍼파라미터 설정과 지속적인 조정을 통해 더 나은 성능의 모델을 만들 수 있다.
'인공지능' 카테고리의 다른 글
| [최적화] Batch Size와 경사 하강법(Gradient Descent) (0) | 2025.03.06 |
|---|---|
| [머신러닝] 선형회귀와 경사하강법 (수식 포함) (1) | 2025.02.13 |
| [머신러닝] 지도학습, 비지도학습, 자기지도학습, 강화학습 (1) | 2025.02.10 |