

Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- kt_aivle
- 후기
- 배치사이즈
- 인공지능
- 컴공
- LLM
- 논문리뷰
- kt_aivle_school
- git
- CSS
- 머신러닝
- HTML
- kt_부트캠프
- 개념
- Github
- 프론트엔드
- 멋쟁이사자처럼
- 페이지전환
- 테킷
- 티스토리챌린지
- 깃
- llm-ma
- 딥러닝
- 딥러닝개념
- 바틀넥
- 보상함수
- 오블완
- 깃허브
- 이미지
- kt부트캠프
Archives
- Today
- Total
공부하는 안씨의 기록
[논문리뷰] Large language model based multi-agents: A survey of progress and challenges 본문
논문 리뷰
[논문리뷰] Large language model based multi-agents: A survey of progress and challenges
an씨 2024. 11. 27. 15:39Large language model based multi-agents: A survey of progress and challenges
위 서베이 논문을 읽고, 정리해본 내용이다.
졸업 프로젝트를 진행하기 앞서 관련 선행 연구를 이해하고, 개념을 정리하기 위해 리뷰해보았다.
1. 배경
LLM-MA 시스템의 기본 개념
- LLM-MA 시스템은 단일 LLM 에이전트의 고급 계획 및 추론 능력을 확장하여 여러 에이전트가 협력하여 문제를 해결하거나 세계를 시뮬레이션하도록 설계된 시스템.
- 이 시스템은 각 에이전트가 특정 역할과 능력을 가지며, 상호작용과 협력을 통해 집단 지능을 발휘함.
- 단일 LLM 시스템이 개별 작업에 집중하는 반면, LLM-MA는 다중 에이전트의 상호작용과 협업을 통해 더 복잡한 작업을 처리
단일 에이전트 시스템과의 차이
특징 단일 에이전트 시스템 다중 에이전트 시스템 (LLM-MA)
| 역할 | 하나의 모델이 모든 작업 수행 | 다양한 역할의 에이전트들이 협력 |
| 목표 | 개별 작업 수행 | 협력과 집단 지능 활용 |
| 상호작용 | 외부 환경과만 상호작용 | 에이전트 간 통신과 협업 포함 |
| 적용 범위 | 단일 작업 또는 문제 | 복잡한 문제 해결 및 세계 시뮬레이션 |
2. LLM-MA 구성요소
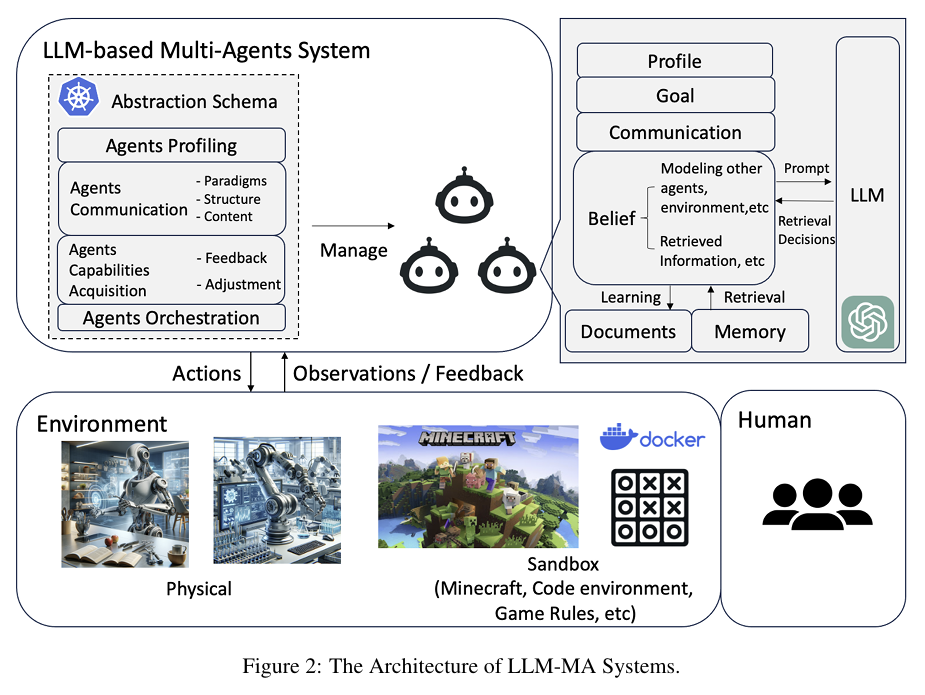
2.1 환경 인터페이스 (Agents-Environment Interface)
- 에이전트가 상호작용하는 환경을 정의
- 샌드박스(Sandbox): 이 환경은 가상으로 구축된 시뮬레이션 환경으로, 에이전트가 규칙에 따라 자유롭게 상호작용하고 작업을 수행.
- 물리적 환경(Physical): 로봇 작업과 같은 현실 세계와의 상호작용.
- 환경 없음(None): 에이전트 간 내부 상호작용에만 집중.
2.2 에이전트 프로파일링 (Agent Profiling)
- 에이전트 프로파일링은 특정 작업을 수행하기 위해 설계된 에이전트의 특성, 능력, 행동을 정의하는 과정.
- 프로파일링은 에이전트가 시스템 내에서 고유한 역할을 수행하게 함.
- 프로파일링의 구성 요소:
- 역할(Role): 에이전트가 수행해야 할 작업의 종류와 책임
- 능력(Capabilities): 특정 작업을 완료하기 위해 에이전트가 보유한 기술 및 지식
- 행동 제약(Behavioral Constraints): 에이전트의 행동을 제한하거나 특정방식으로 조정하는 규칙
- 프로파일링 방법:
- 사전 정의 (Pre-defined): 미리 설정된 역할.
- 모델 생성 (Model-Generated): LLM을 통해 자동 생성.
- 데이터 기반 (Data-Derived): 기존 데이터셋에서 특성 추출.
2.3 에이전트 간 통신 (Agent Communication)
-
- 통신 패러다임: 협력(Cooperative), 토론(Debate), 경쟁(Competitive).
- 통신 구조: 계층형(Layered), 분산형(Decentralized), 중앙 집중형(Centralized), 메시지 풀(Shared Message Pool).에이전트가 정보를 교환하고 협력하는 방식

- 계층적(Layered): 중앙에서 명령이 전달되고, 하위 에이전트가 이를 실행
- 분산형(Decentralized): 모든 에이전트가 동등한 위치에서 서로 상호작용하며, 중앙 제어가 없음
- 중앙 집중형(Centralized): 하나의 에이전트가 모든 통신을 조율
- 공유 메시지 풀(Shared Message Pool): 에이전트들이 메시지를 게시하고, 필요한 메시지를 읽는 방식으로 통신
2.4 에이전트 능력 습득 (Agent Capability Acquisition)
- 에이전트가 피드백을 통해 학습하고 적응하는 방법:
- 피드백
- 환경(Environment):
- 에이전트는 환경에서 직접적인 피드백을 받으며, 이는 행동 결과에 따라 변화한다. 예를 들어, 게임에서 점수를 통해 행동의 성공 여부를 평가 받는 경우.
- 에이전트 상호작용(Agent Interactions):
- 에이전트는 다른 에이전트와 상호작용하여 협력하거나 논쟁하는 과정에서 학습한다. 이러한 상호작용은 에이전트 간 의사결정을 개선하고 집단적 목표를 달성하는 데 도움을 준다..
- 인간 피드백(Human Feedback):
- 에이전트는 인간 사용자가 제공하는 피드백을 통해 행동을 조정하고 학습할 수 있다. 예를 들어, 사람이 에이전트가 생성한 텍스트의 정확성을 평가하고 수정 사항을 제안하는 경우.
- 피드백 없음(None):
- 특정 상황에서는 피드백 없이 단순히 사전 프로그래밍된 규칙에 따라 행동하거나 결과를 기록하는 데 초점이 맞춰질 수 있다.
- 환경(Environment):
- 메모리(Memory):
- 에이전트는 이전 상호작용 데이터를 저장하고 필요할 때 이를 검색하여 미래의 의사결정에 활용할 수 있다. 예를 들어, 특정 상황에서 과거의 성공적인 행동을 기반으로 전략을 수정하는 경우.
- 자율 진화(Self-Evolution):
- 에이전트는 초기 설정된 목표나 계획을 스스로 평가하고 수정할 수 있다. 이는 에이전트가 동적인 환경에서 더욱 효과적으로 작동할 수 있도록 함.
- 동적 생성(Dynamic Generation):
- 작업 중에 새로운 에이전트를 실시간으로 생성하여 특정 목표를 달성하거나 환경 변화에 적응할 수 있다.
- 학습 및 적응 전략: 메모리, 자율 진화(Self-Evolution), 동적 생성(Dynamic Generation).
- 피드백
- 에이전트는 학습과 적응을 위해 다음과 같은 전략을 사용.
3. 응용 사례
3.1 문제 해결
- 소프트웨어 개발: 제품 관리자, 프로그래머, 테스터 등 역할을 맡아 협력.
- 로봇 협력: 물리적 환경에서 복잡한 작업 수행.
- 과학 실험: 실험 계획, 데이터 분석, 로봇 조작.
- 과학적 토론: 문제 해결을 위한 협력적 논의.
3.2 세계 시뮬레이션 (World Simulation)
- 사회적 시뮬레이션: 사회 행동, 의견 확산 모델링. 에이전트는 가상의 사회적 행동을 모델링하여 인간 사회의 다양한 현상을 연구하는 데 기여할 수 있음. 예를 들어, 의견 확산 또는 협력 행동의 동역학을 연구하는 데 사용.
- 게임 시뮬레이션: 다양한 역할을 맡아 게임 전략 탐구. 에이전트는 게임 내에서 다양한 역할을 수행하며 전략을 탐구할 수 있음. 이는 게임 개발자와 연구자가 새로운 전략을 실험하고 플레이어 행동을 분석하는 데 유용
- 경제 시뮬레이션: 금융 시장, 정책 결정 모델링. 에이전트는 가상 금융 시장을 시뮬레이션하여 경제적 의사결정의 결과를 탐구할 수 있음. 예를 들어, 시장 변동성이나 정책 변경의 영향을 분석하는 데 사용
- 정책 결정: 정책 효과와 사회적 영향 평가. LLM-MA는 정책 결정 및 실행의 결과를 예측하는 데 사용될 수 있음. 예를 들어, 새로운 법률이나 규정이 특정 사회적 또는 경제적 결과에 미치는 영향을 분석하는 데 유용
4. 데이터셋과 벤치마크
LLM-MA 연구에 활용할 수 있는 주요 데이터셋과 벤치마크:
세계 시뮬레이션 작업에서 사용되는 데이터셋:
- Werewolf:가상의 게임 환경에서 협력적 의사결정과 경쟁적 행동을 평가하는 데 사용
- Avalon: 에이전트 간 협력과 토론 능력을 테스트하기 위한 게임 시뮬레이션 데이터셋
- MovieLens-1M: 추천 시스템 연구에 사용되는 데이터셋으로, 에이전트가 사용자-아이템 상호작용을 모델링하는 능력을 평가
5. 도전 과제와 기회
- 멀티모달 환경 확장: 텍스트 외에 이미지, 음성 등 다양한 데이터 타입 처리 필요.
- 환각(hallucination) 문제: 에이전트 간 잘못된 정보의 확산 방지.
- 예시: 하나의 에이전트가 잘못된 데이터를 생성하면, 이를 기반으로 다른 에이전트가 잘못된 결정을 내릴 수 있음
- 해결 방안:
- 환각을 감지하고 수정할 수 있는 메커니즘 개발.
- 에이전트 간의 피드백 루프를 통해 정보의 정확성을 검증.
- 집단 지능 최적화: 에이전트 네트워크 전체의 협력을 강화하는 기술 부족.
- 도전 과제:
- 각 에이전트가 고유한 역할과 책임을 가지고 있으면서도 협력적으로 작동하도록 설계.
- 에이전트 간의 충돌을 관리하고, 갈등을 해결하는 메커니즘 개발.
- 기회: 집단 지능을 최적화하면, 복잡한 문제를 해결하거나 창의적인 아이디어를 생성하는 데 있어 LLM-MA 시스템의 능력이 크게 향상될 것임.
- 도전 과제:
- LLM-MA 시스템의 주요 강점은 집단 지능을 발휘할 수 있다는 점. 그러나 에이전트 간의 상호작용을 최적화하고, 개별 에이전트의 기여를 집단적 성공으로 연결하는 것은 여전히 도전 과제로 남아 있다.
- 시스템 확장성: 대규모 에이전트 운영 시 자원 관리와 성능 최적화 필요.
- 도전 과제:
- 에이전트 수가 증가해도 성능이 급격히 저하되지 않도록 확장 가능한 아키텍처 설계.
- 계산 비용을 최적화하는 알고리즘 개발.
- 기회: 확장성이 향상되면, LLM-MA 시스템이 대규모 산업 애플리케이션에 도입될 가능성이 열립니다.
- 도전 과제:
- LLM-MA 시스템은 에이전트 수가 증가할수록 계산 자원 요구가 급증. 이는 대규모 시스템을 설계하거나 운영하는 데 있어 중요한 제약 조건이 될 수 있음.
- 평가 및 벤치마크 부족: 현실 세계와 유사한 복잡한 평가 환경 부족.
- 예시:
- LLM-MA 시스템이 다양한 도메인에서 얼마나 잘 작동하는지 측정하기 위한 테스트 환경.
- 복잡한 시뮬레이션 작업에서 에이전트의 협력과 상호작용을 평가하기 위한 새로운 메트릭 개발.
- 해결 방안:
- 다양한 응용 분야에 적합한 벤치마크 개발.
- 현실 세계에서 수집된 데이터를 기반으로 한 대규모 테스트베드 구축.
- 예시:
- LLM-MA 시스템의 성능을 평가하기 위한 포괄적인 벤치마크가 부족함. 현재 사용 가능한 데이터셋과 벤치마크는 제한적이며, 현실 세계의 복잡한 시나리오를 충분히 반영하지 못함.
'논문 리뷰' 카테고리의 다른 글
'논문 리뷰' Related Articles
more


